Bible Research Tool
This has been my longest running project, consumming more hours from me than any of the others.
I listen to a lot of messages about the Bible. I take notes, and within the messages are references in the Bible. Many times the speaker can give a direct reference, other times he will only give an approximate location or even less, maybe a few words of a quotation.
I am not about to have incomplete notes. A few words in quotations may not capture the thought, and I could easily forget the context or why a certain utterance made sense while listening to a message but not necessarily while reviewing it. Thus, I needed a way to find things in the Bible–verses, references, footnotes, cross references, original language text–and I need to do it at the speed someone speaks. Tools already exist for those things, but they cannot keep up with the speed of thought.
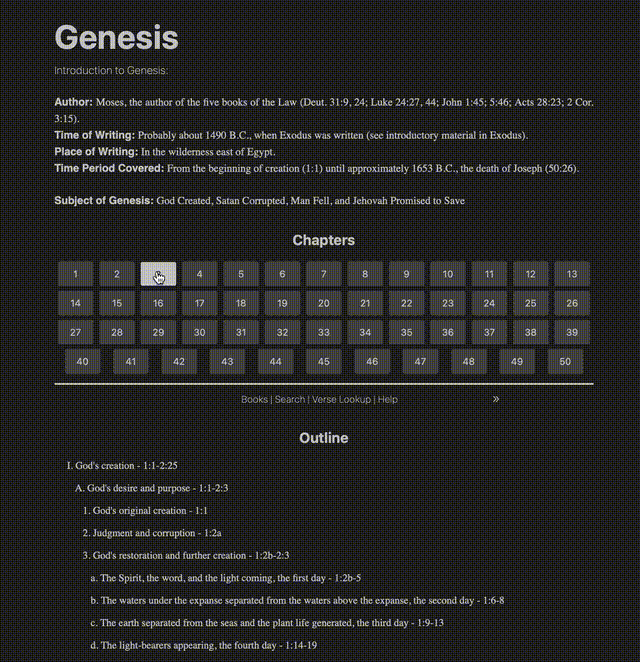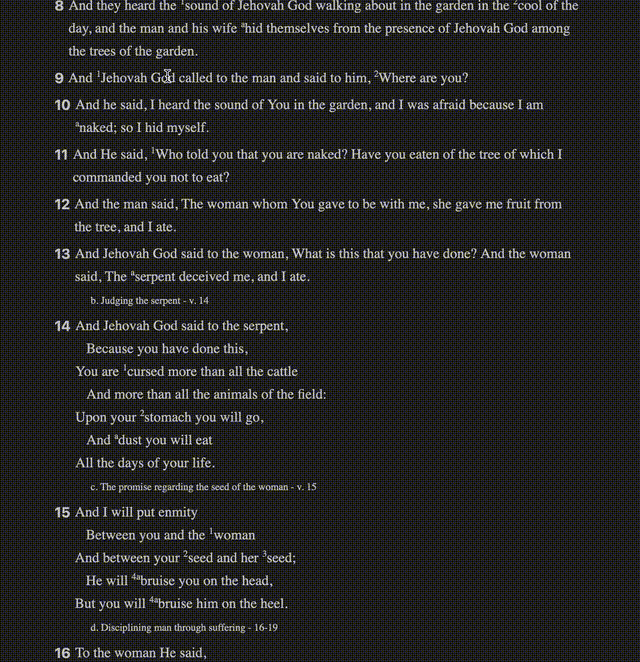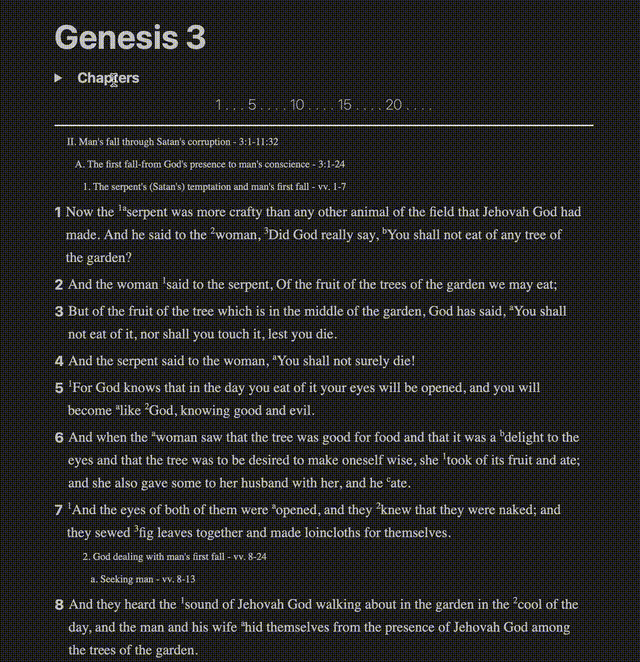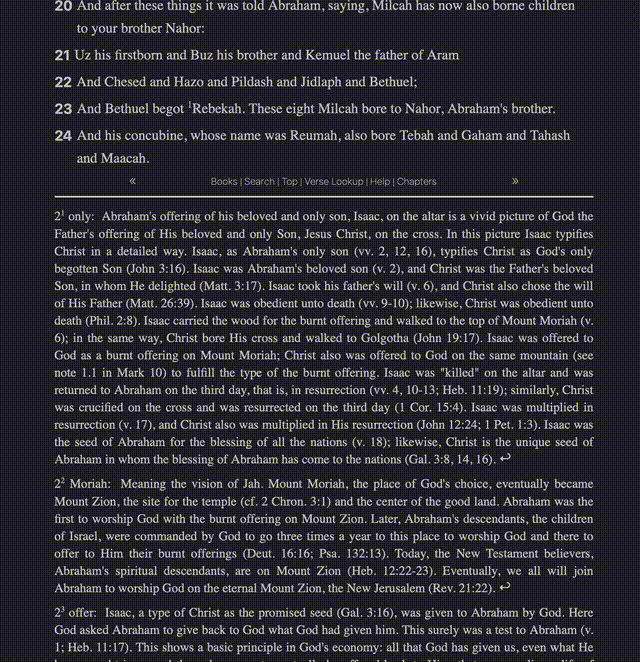
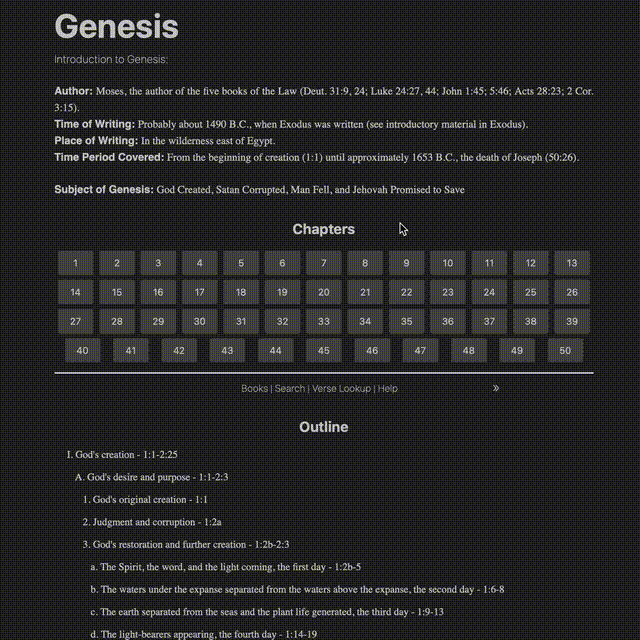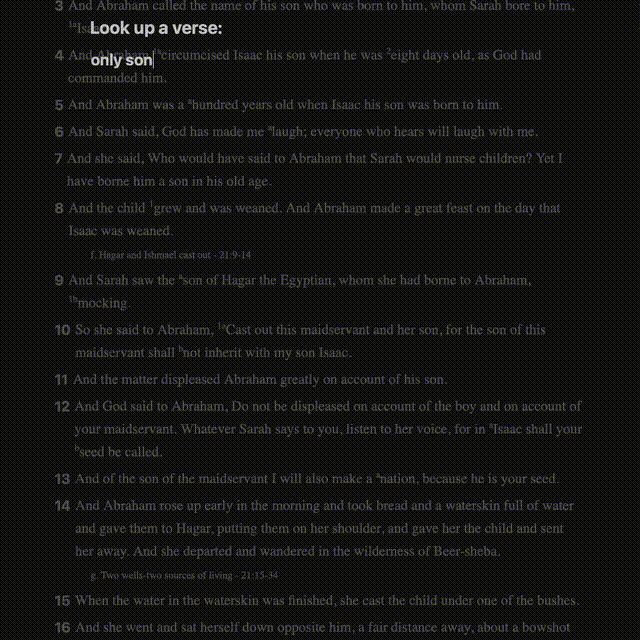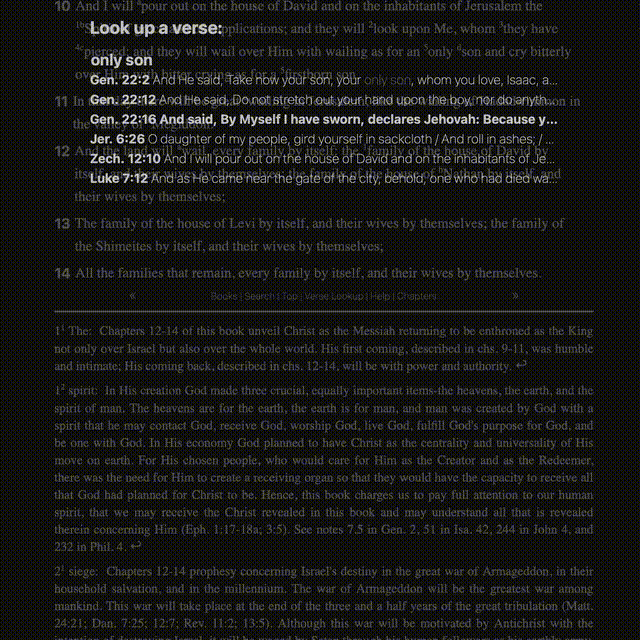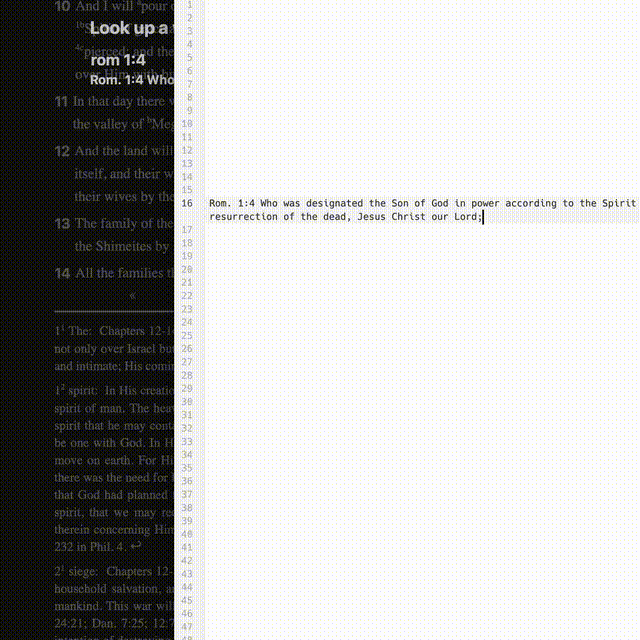
It started as a very basic reader
Features
- Keyboard navigation for primary use cases
- Instant, full-text search of verses
- Instant, full-text search of footnotes and cross-references
- Inline verse-reference retrieval
- Clipboard access
- Verse list retrieving
- Text-to-speach automatic reading
- Viewing of original Biblical text (Hebrew, Greek, etc.) along with searching Strong’s concordance
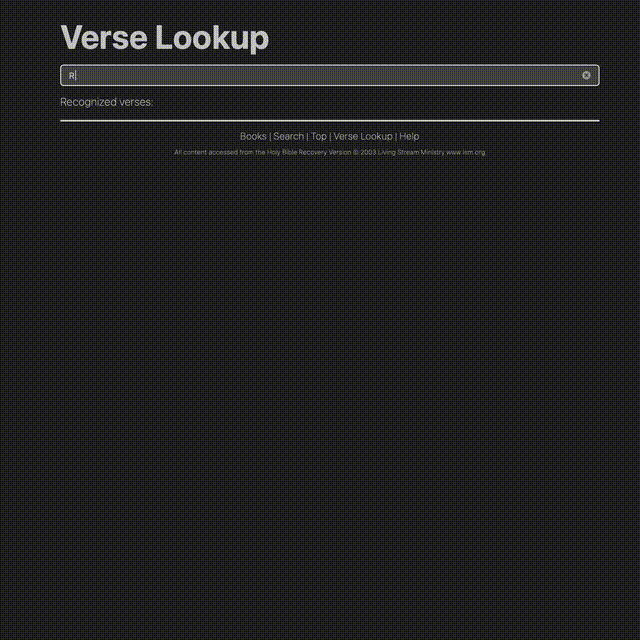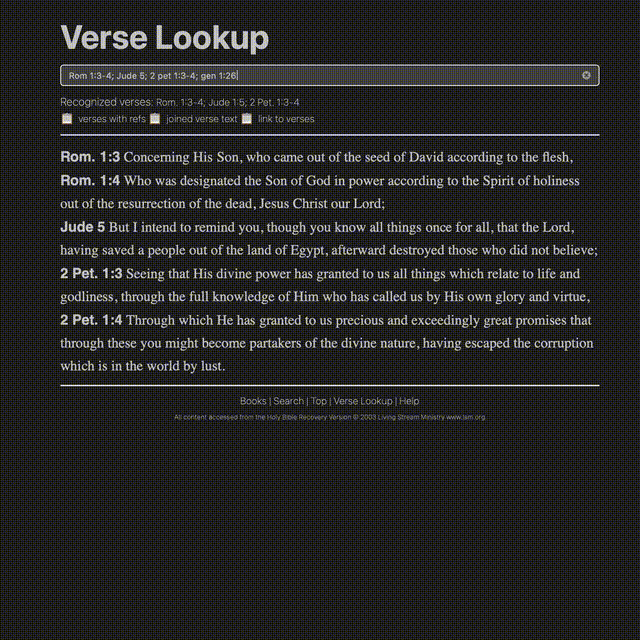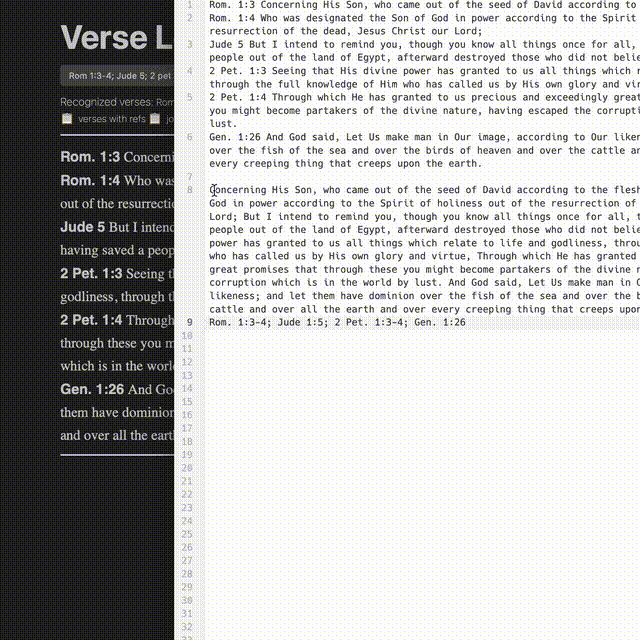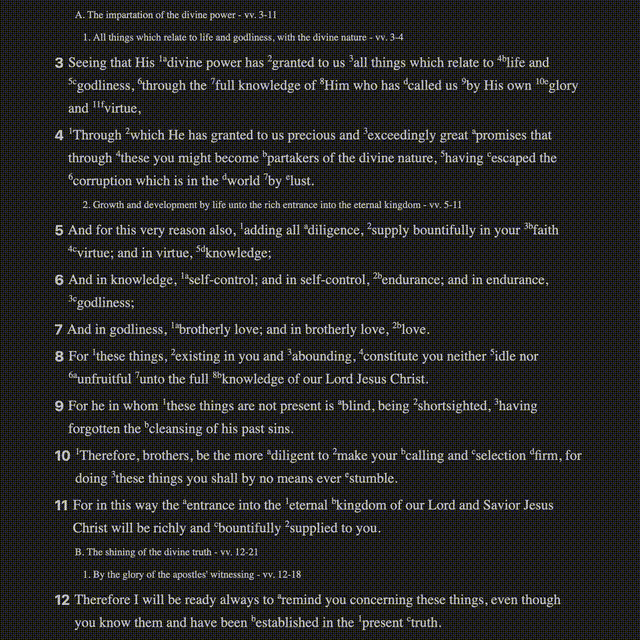
A Journey in Parsing
In the first gif, you can see text with superscripts, footnotes, cross-references, and verses that link to places. The source I had for all of this came as plain text. Everything was smooshed together in disparate places, seemingly having little rhyme or reason.
The first code I wrote for this project was simply a text file parser, that I ultimately ended up writing to run in multiple processes because it was so inefficient at finding the data it needed to, plus there was competition between processes for database access. I think the final script took a few hours to run. I had a separate process for every book, and ultimately the length of time it took was the length of time it took for that single longest book to be parsed (looking at you, Psalms).
Tech Stack
This thing went through many iterations of experimenting with different technologies. At one point I was generating it as a static site, comparing page load times between disk access vs serving out of Redis. Other times it had analytics. One time I was focusing on SEO optimization, at the end I pulled it completely from the public web to be just for my personal use. The point is to say I had the opportunity to play with a lot of techonlogies in making this happen, and I’m happy about how it iteratively got better and ultimately got to where it is today.
- Backend: php
- Database: SQLite (originally MySQL)
- Frontend: plain Javascript
It’s actually about as basic as you can get for a web application that uses a database. The site works without javascript, but key features are missing.